As data collections become larger and larger, even on a daily basis, the world is already caught in the era of data deluge where we have much more data than what we can move, store, let alone analyze. Although Database Management Systems (DBMS) remain overall the predominant data analysis technology by providing unparalleled flexibility and performance when it comes to query processing, scalability and accuracy, they are rarely used for emerging applications such as scientific analysis and social networks.
This is largely due to the prohibitive initialization cost, complexity (loading the data, configuring the physical design, etc.) and the increased “data-to-query” time, i.e., the time spent from when the data is available until the moment where the answer to a query is obtained. The data-to-query time is of critical importance as it defines the moment when a database system becomes usable and thus useful.
For example, a scientist needs to quickly examine a few Terabytes of new data in search of certain properties. Even though only few attributes might be relevant for the task, the entire data must first be loaded inside the database. For large amounts of data, this means a few hours of delay. Additionally, the optimal storage and access patterns may change even on daily basis depending on the new data, its properties, correlations, as well as the ways that the scientists navigate through the data and the ways their understanding and data interpretation evolve. In such scenarios, no up-front physical design decision can be optimal in light of a completely dynamic and ever-evolving access pattern. As a result, many times scientists compromise functionality and flexibility and rely on custom solutions for their data management tasks in order to achieve bread-and-butter functionality of a DBMS, delaying scientific understanding and progress.
In this project, we recognize a new need, which is a direct consequence of the data deluge. We propose a new generation of data management systems which make database systems more accessible to the user by eliminating major bottlenecks of current state of the art technology while still maintaining the entire feature set of a modern database system. To achieve that, we extend traditional database architectures to perform the query processing in-situ on the data, according to the query demands. Data files are considered an integral part of the system and the main copy of the data remains outside the data management system, under formats that are chosen by the users. In contrast with conventional DBMS, no time is spent loading the data or tuning the database system. Instead, this is done progressively and adaptively as a side effect of query execution. By not loading the data in advance into the database we avoid: a) the resource and time-consuming procedure of loading the entire data set and b) taking critical design decisions on the physical database design before real user queries start hitting the system.
ViDa: Transforming Raw Data into Information THROUGH VIRTUALIZATION
Modern data management systems – a multi-billion dollar industry – offer tremendous querying power on large datasets, as long as the data is structured and formatted in a pre-specified way. This static nature of traditional database system architecture becomes an obstacle to data analysis. Integrating and ingesting (loading) data into databases is quickly becoming a bottleneck in face of massive data as well as increasingly heterogeneous data formats. Still, state-of-the-art approaches typically rely on copying and transforming data into one (or few) repositories. Queries, on the other hand, are often ad-hoc and supported by pre-cooked operators which are not adaptive enough to optimize access to data. As data formats and queries increasingly vary, there is a need to depart from the current status quo of static query processing primitives and build dynamic, fully adaptive architectures.
A change of paradigm is required for data analysis processes to leverage the amounts of diverse data available. Database systems must become dynamic entities whose construction is lightweight and fully adaptable to the datasets and the queries. Data virtualization, i.e, abstracting data out of its form and manipulating it regardless of the way it is stored or structured, is a promising step in the right direction. To offer unconditional data virtualization, however, a database system must abolish static decisions like pre-loading data and using “pre-cooked” query operators. This dynamic nature must also be extended to users, who must be able to express data analysis processes in a query language of their choice.
We therefore build ViDa, a system which reads data in its raw format and processes queries using adaptive, just-in-time operators. Our key insight is use of virtualization, i.e., abstracting data and manipulating it regardless of its original format, and dynamic generation of operators. ViDa’s query engine is generated just-in-time; its caches and its query operators adapt to the current query and the workload, while also treating raw datasets as its native storage structures. Finally, ViDa features a language expressive enough to support heterogeneous data models, and to which existing languages can be translated. Users therefore have the power to choose the language best suited for an analysis.
With ViDa, we envision transforming databases into “virtual” instances of the raw data, with users spawning new instances as needed where they can access, manipulate and exchange data independently of its physical location, representation or resources used. Performance optimizations are transparent, entirely query-driven and performed autonomously during query execution. Constant changes to a database, including schema changes, are not only supported but encouraged so that users can better calibrate their “view” over the underlying data to their needs. Data analysts build databases by launching queries, instead of building databases to launch queries. The database system becomes naturally suited for data integration.
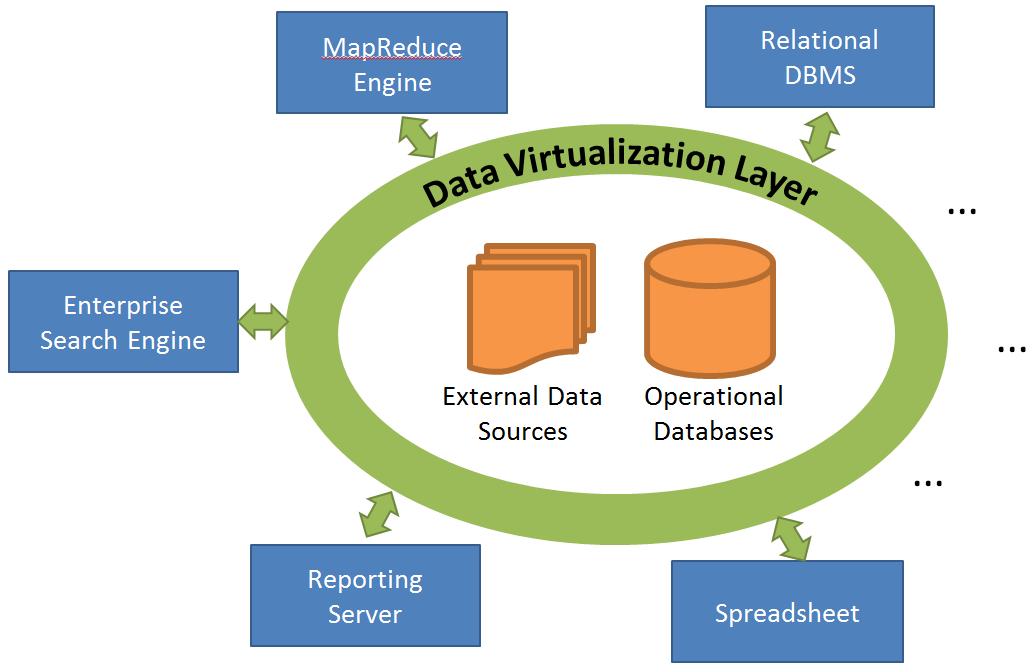
The figure above depicts a business intelligence architecture based on data virtualization. A transparent virtualization layer encompasses all data and enables efficient data access. Data processing frameworks use the virtualization layer to provide fast end-user services and seamlessly share data access optimizations.
People involved: Ioannis Alagiannis, Renata Borovica, Miguel Branco, Manos Karpathiotakis, Erietta Liarou, Manolis Karpathiotakis
This project was funded by:
- the ERC Grant CoG: Project 617508.
- the Swiss National Science Foundation in the means of the grant for the SINERGIA Project “Modern Storage: From Hard Disks, to Solid State Storage, to Persistent Main Memory”.
- BigFoot 2012 – STREP project Funded by EU – FP7 Call 8 – Objective 1.2: Cloud Computing, Internet of Services and Advanced Software Engineering.
This project is part of Proteus DBMS (proteusdb.com).