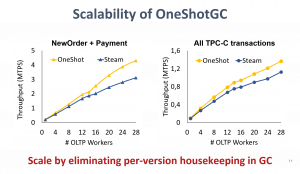
Most modern in-memory online transaction processing (OLTP) engines rely on multi-version concurrency control (MVCC) to provide data consistency guarantees in the presence of conflicting data accesses. MVCC improves concurrency by generating a new version of a record on every write, thus increasing the storage requirements. Existing approaches rely on garbage collection and chain consolidation to reduce the length of version chains and reclaim space by freeing unreachable versions. However, finding unreachable versions requires the traversal of long version chains, which incurs random accesses right into the critical path of transaction execution, hence limiting scalability.
Our research introduces OneShotGC, a new multi-version storage design that eliminates version traversal during garbage collection, with minimal discovery and memory management overheads. OneShotGC leverages the temporal correlations across versions to opportunistically cluster them into contiguous memory blocks that can be released in one shot. We implement OneShotGC in Proteus (add a link to Proteus https://proteusdb.com/ ) and use YCSB and TPC-C to experimentally evaluate its performance with respect to the state-of-the-art, where we observe an improvement of up to 2x in transactional throughput.
Computation
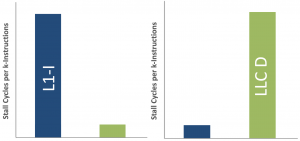
Micro-architectural behavior of traditional disk-based online transaction processing (OLTP) systems has been investigated extensively over the past couple of decades. Results show that traditional OLTP mostly under-utilize the available micro-architectural resources. In-memory OLTP systems, on the other hand, process all the data in mainmemory, and therefore, can omit the buffer pool. In addition, they usually adopt more lightweight concurrency control mechanisms, cache-conscious data structures, and cleaner codebases since they are usually designed from scratch. Hence, we expect significant differences in micro-architectural behavior when running OLTP on platforms optimized for inmemory processing as opposed to disk-based database systems. In particular, we expect that in-memory systems exploit micro architectural features such as instruction and data caches significantly better than disk-based systems.
This research sheds light on the micro-architectural behavior of in-memory database systems by analyzing and contrasting it to the behavior of disk-based systems when running OLTP workloads. The results show that despite all the design changes, in-memory OLTP exhibits very similar microarchitectural behavior to disk-based OLTP systems: more than half of the execution time goes to memory stalls where L1 instruction misses and the long-latency data misses from the last-level cache are the dominant factors in the overall stall time. Even though aggressive compilation optimizations can almost eliminate instruction misses, the reduction in instruction stalls amplifies the impact of last-level cache data misses. As a result, the number of instructions retired per cycle barely reaches one on machines that are able to retire up to four for both traditional disk-based and new generation in-memory OLTP.
Publications
Field Guide to Northern Tree-related Microhabitats: Descriptions and size limits for their inventory in boreal and hemiboreal forests of Europe and North America
Swiss Federal Institute for Forest, Snow and Landscape Research WSL, Switzerland, 2024.Data Champions Lunch Talks – Green Bytes: Data-Driven Approaches to EPFL Sustainability
Data Champions Lunch Talks – Green Bytes: Data-Driven Approaches to EPFL Sustainability, EPFL, CM 1 221, April 18, 2024.Comparison of Three Viral Nucleic Acid Preamplification Pipelines for Sewage Viral Metagenomics
Food and Environmental Virology. 2024. DOI : 10.1007/s12560-024-09594-3.How to Support Students to Develop Skills that Promote Sustainability
Teaching Transversal Skills for Engineering Studens: A Practical Handbook of Activities with Tangibles; EPFL, 2024.How to Support Students Giving Each Other Constructive Feedback, Especially When It Is Difficult to Hear
Teaching Transversal Skills for Engineering Studens: A Practical Handbook of Activities with Tangibles; EPFL, 2024.How teachers can use the 3T PLAY trident framework to design an activity that develops transversal skills
Teaching Transversal Skills for Engineering Studens: A Practical Handbook of Activities with Tangibles; EPFL, 2024.The conceptual foundations of innate immunity: Taking stock 30 years later
Immunity. 2024-04-09. Vol. 57, num. 4, p. 613-631. DOI : 10.1016/j.immuni.2024.03.007.Radio-Activities: Architecture and Broadcasting in Cold War Berlin
Cambridge, MA; London: MIT Press, 2024.No Last One
Revue Matières. 2024. num. 18.All That is Solid
Transcalar Prospects in Climate Crisis; Zurich: Lars Müller, 2024.Characterization of the gut-bone marrow axis through bile acid signaling
Lausanne, EPFL, 2024.Studies of crystal collimation for heavy ion operation at the LHC
Lausanne, EPFL, 2024.Engineering novel protein interactions with therapeutic potential using deep learning-guided surface design
Lausanne, EPFL, 2024.Querying the Digital Archive of Science: Distant Reading, Semantic Modelling and Representation of Knowledge
Lausanne, EPFL, 2024.Hybrid organic/metal-oxide shells on semiconductor nanocrystals via colloidal atomic layer deposition
Lausanne, EPFL, 2024.Electrical and Optical Manifestations of Flat Band Physics in Van der Waals Materials
Lausanne, EPFL, 2024.Plasmonically enhanced molecular junctions for investigation of atomic-scale fluctuations in self-assembled monolayers
Lausanne, EPFL, 2024.Exact Obstacle Avoidance for Robots in Complex and Dynamic Environments Using Local Modulation
Lausanne, EPFL, 2024.S-acylation and lipid exchange at the ER-Golgi membrane contact sites regulate pathogen entry in human cells
Lausanne, EPFL, 2024.Serial Dependence in Human Visual Perception and Decision-Making
Lausanne, EPFL, 2024.Data-Driven Methods for Controller Design in Atomic Force Microscopy
Lausanne, EPFL, 2024.Quantum-mechanical effects in photoluminescence from thin crystalline gold films
Light: Science & Applications. 2024. Vol. 13, num. 91. DOI : 10.1038/s41377-024-01408-2.Quantifying the effects of rainfall temporal variability on landscape evolution processes
EGU 2024, Viena, April 14–19, 2024.Towards a metabolic theory of catchments: scaling of water and carbon fluxes with size
EGU General Assembly 2024, Vienna, Austria, April 14-19, 2024.Biohybrid Superorganisms—On the Design of a Robotic System for Thermal Interactions With Honeybee Colonies
IEEE Access. 2024. Vol. 12, p. 50849-50871. DOI : 10.1109/ACCESS.2024.3385658.Dataset to accompany publication “Quantum-mechanical effects in photoluminescence from thin crystalline gold films”
2024.Impact of CO2-rich seawater injection on the flow properties of basalts
International Journal of Greenhouse Gas Control. 2024-04-19. Vol. 134, p. 104128. DOI : 10.1016/j.ijggc.2024.104128.Architecture of a decentralised decision support system for futuristic beehives
Biosystems Engineering. 2024. Vol. 240, p. 56-61. DOI : 10.1016/j.biosystemseng.2024.02.017.TSLAM: a tag-based object-centered monocular navigation system for augmented manual woodworking.
Construction Robotics. 2024-04-16. Vol. 8, num. 4. DOI : 10.1007/s41693-024-00118-w.Water weakening and the compressive brittle strength of carbonates: Influence of fracture toughness and static friction
International Journal of Rock Mechanics and Mining Sciences. 2024. Vol. 177, p. 105736. DOI : 10.1016/j.ijrmms.2024.105736.Integration of the Pilatus3 detector for soft X-ray diagnostics on TCV
25th Topical Conference on High Temperature Plasma Diagnostics HTPD 2024, Asheville, North Carolina, 21 – 25 April 2024.Siloxide tripodal ligands as a scaffold for stabilizing lanthanides in the +4 oxidation state
Chemical Science. 2024-04-02. DOI : 10.1039/d4sc00051j.High-Permittivity Polysiloxanes for Bright, Stretchable Electroluminescent Devices
Advanced Optical Materials. 2024-04-11. DOI : 10.1002/adom.202400132.An extension of the stochastic sewing lemma and applications to fractional stochastic calculus
Forum Of Mathematics Sigma. 2024-04-11. Vol. 12, p. e52. DOI : 10.1017/fms.2024.32.A bridge between trust and control: computational workflows meet automated battery cycling
Journal Of Materials Chemistry A. 2024-04-03. DOI : 10.1039/d3ta06889g.Capsizing due to friction-induced twist in the failure of stopper knots
Extreme Mechanics Letters. 2024-02-19. Vol. 68, p. 102134. DOI : 10.1016/j.eml.2024.102134.A CTCF-dependent mechanism underlies the Hox timer relation to a segmented body plan
Current Opinion In Genetics & Development. 2024-04-01. Vol. 85, p. 102160. DOI : 10.1016/j.gde.2024.102160.Gradient High-Q Dielectric Metasurfaces for Broadband Sensing and Control of Vibrational Light-Matter Coupling
Advanced Materials. 2024-04-09. DOI : 10.1002/adma.202314279.SOMOphilic alkyne vs radical-polar crossover approaches: The full story of the azido-alkynylation of alkenes
Beilstein Journal Of Organic Chemistry. 2024-04-03. Vol. 20, p. 701-713. DOI : 10.3762/bjoc.20.64.Dielectric elastomer actuator-based valveless pump as Fontan failure assist device: introduction and preliminary study
Interdisciplinary Cardiovascular And Thoracic Surgery. 2024-03-29. Vol. 38, num. 4, p. ivae041. DOI : 10.1093/icvts/ivae041.Tree diversity reduces variability in sapling survival under drought
Journal Of Ecology. 2024-04-08. DOI : 10.1111/1365-2745.14294.Probing structural and dynamic properties of MAPbCl3 hybrid perovskite using Mn2+ EPR
Dalton Transactions. 2024-04-03. DOI : 10.1039/d4dt00116h.Benchmarking machine-readable vectors of chemical reactions on computed activation barriers
Digital Discovery. 2024-03-07. DOI : 10.1039/d3dd00175j.Quantum radio astronomy: Data encodings and quantum image processing
Astronomy And Computing. 2024-02-28. Vol. 47, p. 100796. DOI : 10.1016/j.ascom.2024.100796.Comprehensive Memory Safety Validation: An Alternative Approach to Memory Safety
Ieee Security & Privacy. 2024-04-04. DOI : 10.1109/MSEC.2024.3379947.A Method of Moments Estimator for Interacting Particle Systems and their Mean Field Limit
Siam-Asa Journal On Uncertainty Quantification. 2024-01-01. Vol. 12, num. 2, p. 262-288. DOI : 10.1137/22M153848X.A setup for hard x-ray time-resolved resonant inelastic x-ray scattering at SwissFEL
Structural Dynamics-Us. 2024-03-01. Vol. 11, num. 2, p. 024308. DOI : 10.1063/4.0000236.An aircraft assembly process formalism and verification method based on semantic modeling and MBSE
Advanced Engineering Informatics. 2024-02-20. Vol. 60, p. 102412. DOI : 10.1016/j.aei.2024.102412.Stellar Metallicities and Gradients in the Isolated, Quenched Low-mass Galaxy Tucana
Astrophysical Journal. 2024-04-01. Vol. 965, num. 1, p. 36. DOI : 10.3847/1538-4357/ad25ed.Twisted pair transmission line coil – a flexible, self-decoupled and robust element for 7 T MRI
Magnetic Resonance Imaging. 2024-02-19. Vol. 108, p. 146-160. DOI : 10.1016/j.mri.2024.02.007.3D Printing of Double Network Granular Elastomers with Locally Varying Mechanical Properties
Advanced Materials. 2024-04-04. DOI : 10.1002/adma.202313189.Dopant-additive synergism enhances perovskite solar modules
Nature. 2024-03-04. DOI : 10.1038/s41586-024-07228-z.Proliferation-driven mechanical compression induces signalling centre formation during mammalian organ development
Nature Cell Biology. 2024-04-03. DOI : 10.1038/s41556-024-01380-4.Spin-Reorientation-Driven Linear Magnetoelectric Effect in Topological Antiferromagnet Cu3TeO6
Physical Review Letters. 2024-02-26. Vol. 132, num. 9, p. 096701. DOI : 10.1103/PhysRevLett.132.096701.Is There a Special Role for Ovarian Hormones in the Pathogenesis of Lobular Carcinoma?
Endocrinology. 2024-03-29. Vol. 165, num. 5, p. bqae031. DOI : 10.1210/endocr/bqae031.Stick-slip-to-stick transition of liquid oscillations in a U-shaped tube
Physical Review Fluids. 2024-03-19. Vol. 9, num. 3, p. 034401. DOI : 10.1103/PhysRevFluids.9.034401.Opportunities and challenges in design and optimization of protein function
Nature Reviews Molecular Cell Biology. 2024-04-02. DOI : 10.1038/s41580-024-00718-y.Impact of beam-coupling impedance on the Schottky spectrum of bunched beam
Journal Of Instrumentation. 2024-03-01. Vol. 19, num. 3, p. P03017. DOI : 10.1088/1748-0221/19/03/P03017.Gaussian universality of perceptrons with random labels
Physical Review E. 2024-03-08. Vol. 109, num. 3, p. 034305. DOI : 10.1103/PhysRevE.109.034305.Diffusion of brain metabolites highlights altered brain microstructure in type C hepatic encephalopathy: a 9.4 T preliminary study
Frontiers In Neuroscience. 2024-03-20. Vol. 18, p. 1344076. DOI : 10.3389/fnins.2024.1344076.Teaching about non-deterministic physics: an almost forgotten fundamental contribution of Marie Curie
European Journal Of Physics. 2024-05-01. Vol. 45, num. 3, p. 035803. DOI : 10.1088/1361-6404/ad312e.The angiogenic growth of cities
Journal Of The Royal Society Interface. 2024-04-03. Vol. 21, num. 213, p. 20230657. DOI : 10.1098/rsif.2023.0657.Learning Weakly Convex Regularizers for Convergent Image-Reconstruction Algorithms
Siam Journal On Imaging Sciences. 2024-01-01. Vol. 17, num. 1, p. 91-115. DOI : 10.1137/23M1565243.Euclid: Improving the efficiency of weak lensing shear bias calibration
Astronomy & Astrophysics. 2024-03-28. Vol. 683, p. A240. DOI : 10.1051/0004-6361/202347833.Randomized flexible GMRES with deflated restarting
Numerical Algorithms. 2024-03-28. DOI : 10.1007/s11075-024-01801-3.An interior penalty coupling strategy for isogeometric non-conformal Kirchhoff-Love shell patches
Engineering With Computers. 2024-03-27. DOI : 10.1007/s00366-024-01965-5.Stress tolerance of lightweight glass-free PV modules for vehicle integration
Epj Photovoltaics. 2024-04-01. Vol. 15, p. 10. DOI : 10.1051/epjpv/2024003.On the Arithmetic and Geometric Fusion of Beliefs for Distributed Inference
Ieee Transactions On Automatic Control. 2024-04-01. Vol. 69, num. 4, p. 2265-2280. DOI : 10.1109/TAC.2023.3330405.Alpha1-antitrypsin improves survival in murine abdominal sepsis model by decreasing inflammation and sequestration of free heme
Frontiers In Immunology. 2024-03-18. Vol. 15, p. 1368040. DOI : 10.3389/fimmu.2024.1368040.Quantitative prediction of crystallization in laser powder bed fusion of a Zr-based bulk metallic glass with high oxygen content
Materials & Design. 2024-03-01. Vol. 239, p. 112744. DOI : 10.1016/j.matdes.2024.112744.A cut-cell method for the numerical simulation of 3D multiphase flows with strong interfacial effects
Journal Of Computational Physics. 2024-02-26. Vol. 504, p. 112846. DOI : 10.1016/j.jcp.2024.112846.Speciation of Lanthanide Metal Ion Dopants in Microcrystalline All-Inorganic Halide Perovskite CsPbCl3
Journal Of The American Chemical Society. 2024-03-28. Vol. 146, num. 14, p. 9554-9563. DOI : 10.1021/jacs.3c11427.Can Gas Consumption Data Improve the Performance of Electricity Theft Detection?
Ieee Transactions On Industrial Informatics. 2024-03-18. DOI : 10.1109/TII.2024.3371991.Design and in vitro Characterization of a Wearable Multisensing System for Hydration Monitoring
Ieee Transactions On Instrumentation And Measurement. 2024-01-01. Vol. 73, p. 1-11. DOI : 10.1109/TIM.2024.3369161.Gamma-ray Spectroscopy in Low-Power Nuclear Research Reactors
Journal Of Nuclear Engineering. 2024-03-01. Vol. 5, num. 1, p. 26-43. DOI : 10.3390/jne5010003.Accretion Disk Size and Updated Time-delay Measurements in the Gravitationally Lensed Quasar SDSS J165043.44+425149.3
Astrophysical Journal. 2024-04-01. Vol. 964, num. 2, p. 173. DOI : 10.3847/1538-4357/ad3069.The molecular scale mechanism of deposition ice nucleation on silver iodide
Environmental Science-Atmospheres. 2024-02-15. Vol. 4, num. 2, p. 243-251. DOI : 10.1039/d3ea00140g.Multi-Ported GC-eDRAM Bitcell with Dynamic Port Configuration and Refresh Mechanism
Journal Of Low Power Electronics And Applications. 2024-03-01. Vol. 14, num. 1, p. 2. DOI : 10.3390/jlpea14010002.On the Sums over Inverse Powers of Zeros of the Hurwitz Zeta Function and Some Related Properties of These Zeros
Symmetry-Basel. 2024-03-01. Vol. 16, num. 3, p. 326. DOI : 10.3390/sym16030326.Realization of Organocerium-Based Fullerene Molecular Materials Showing Mott Insulator-Type Behavior
Acs Applied Materials & Interfaces. 2024-03-27. Vol. 16, num. 14, p. 17857-17869. DOI : 10.1021/acsami.3c18766.Mean-field transport equations and energy theorem for plasma edge turbulent transport
Journal Of Plasma Physics. 2024-03-15. Vol. 90, num. 2, p. 905900202. DOI : 10.1017/S0022377824000163.Two- and Three-Dimensional Superconducting Phases in the Weyl Semimetal TaP at Ambient Pressure. (vol 10, 288, 2020)
Crystals. 2024-03-01. Vol. 14, num. 3, p. 264. DOI : 10.3390/cryst14030264.Microbial genome collection of aerobic granular sludge cultivated in sequencing batch reactors using different carbon source mixtures
Microbiology Resource Announcements. 2024-03-27. DOI : 10.1128/mra.00102-24.The Extraordinary March 2022 East Antarctica “Heat” Wave. Part II: Impacts on the Antarctic Ice Sheet
Journal Of Climate. 2024-02-01. Vol. 37, num. 3, p. 779-799. DOI : 10.1175/JCLI-D-23-0176.1.The multimodality cell segmentation challenge: toward universal solutions
Nature Methods. 2024-03-26. DOI : 10.1038/s41592-024-02233-6.Euclid: The search for primordial features
Astronomy & Astrophysics. 2024-03-25. Vol. 683, p. A220. DOI : 10.1051/0004-6361/202348162.Search for Inelastic Dark Matter in Events with Two Displaced Muons and Missing Transverse Momentum in Proton-Proton Collisions at p s=13 TeV
Physical Review Letters. 2024-01-23. Vol. 132, num. 4, p. 041802. DOI : 10.1103/PhysRevLett.132.041802.Tumor-educated Gr1+CD11b+cells drive breast cancer metastasis via OSM/IL-6/JAK-induced cancer cell plasticity
Journal Of Clinical Investigation. 2024-03-15. Vol. 134, num. 6, p. e166847. DOI : 10.1172/JCI166847.Search for Scalar Leptoquarks Produced via τ-Lepton-Quark Scattering in pp Collisions at ffiffi s p=13 TeV
Physical Review Letters. 2024-02-08. Vol. 132, num. 6, p. 061801. DOI : 10.1103/PhysRevLett.132.061801.Measurement of the K+ → π+γγ decay
Physics Letters B. 2024-02-13. Vol. 850, p. 138513. DOI : 10.1016/j.physletb.2024.138513.Dynamics of the charge transfer to solvent process in aqueous iodide
Nature Communications. 2024-03-21. Vol. 15, num. 1, p. 2544. DOI : 10.1038/s41467-024-46772-0.Cortical cell assemblies and their underlying connectivity: An in silico study
Plos Computational Biology. 2024-03-01. Vol. 20, num. 3, p. e1011891. DOI : 10.1371/journal.pcbi.1011891.Disulfide-Cross-Linked Tetra-PEG Gels
Macromolecules. 2024-03-25. Vol. 57, num. 7, p. 3058-3065. DOI : 10.1021/acs.macromol.3c02514.Evaluation of controllers for augmentative hip exoskeletons and their effects on metabolic cost of walking: explicit versus implicit synchronization
Frontiers In Bioengineering And Biotechnology. 2024-03-12. Vol. 12, p. 1324587. DOI : 10.3389/fbioe.2024.1324587.Boosting likelihood learning with event reweighting
Journal Of High Energy Physics. 2024-03-20. num. 3, p. 117. DOI : 10.1007/JHEP03(2024)117.Deconvolution of the X-ray absorption spectrum of trans-1,3-butadiene with resonant Auger spectroscopy
Physical Chemistry Chemical Physics. 2024-03-25. DOI : 10.1039/d4cp00053f.The Extraordinary March 2022 East Antarctica “Heat” Wave. Part I: Observations and Meteorological Drivers
Journal Of Climate. 2024-02-01. Vol. 37, num. 3. DOI : 10.1175/JCLI-D-23-0175.1.Measurement of the τ lepton polarization in Z boson decays in proton-proton collisions at √s=13 TeV
Journal Of High Energy Physics. 2024-01-19. num. 1, p. 101. DOI : 10.1007/JHEP01(2024)101.Light-Controlled Multiconfigurational Conductance Switching in a Single 1D Metal-Organic Wire
Acs Nano. 2024-03-22. DOI : 10.1021/acsnano.3c12909.Redox Properties of Flavin in BLUF and LOV Photoreceptor Proteins from Hybrid QM/MM Molecular Dynamics Simulation
Journal Of Physical Chemistry B. 2024-03-22. Vol. 128, num. 13, p. 3069-3080. DOI : 10.1021/acs.jpcb.3c06245.Field Guide to Northern Tree-related Microhabitats: Descriptions and size limits for their inventory in boreal and hemiboreal forests of Europe and North America
Swiss Federal Institute for Forest, Snow and Landscape Research WSL, Switzerland, 2024.Data Champions Lunch Talks – Green Bytes: Data-Driven Approaches to EPFL Sustainability
Data Champions Lunch Talks – Green Bytes: Data-Driven Approaches to EPFL Sustainability, EPFL, CM 1 221, April 18, 2024.Comparison of Three Viral Nucleic Acid Preamplification Pipelines for Sewage Viral Metagenomics
Food and Environmental Virology. 2024. DOI : 10.1007/s12560-024-09594-3.How to Support Students to Develop Skills that Promote Sustainability
Teaching Transversal Skills for Engineering Studens: A Practical Handbook of Activities with Tangibles; EPFL, 2024.How to Support Students Giving Each Other Constructive Feedback, Especially When It Is Difficult to Hear
Teaching Transversal Skills for Engineering Studens: A Practical Handbook of Activities with Tangibles; EPFL, 2024.How teachers can use the 3T PLAY trident framework to design an activity that develops transversal skills
Teaching Transversal Skills for Engineering Studens: A Practical Handbook of Activities with Tangibles; EPFL, 2024.The conceptual foundations of innate immunity: Taking stock 30 years later
Immunity. 2024-04-09. Vol. 57, num. 4, p. 613-631. DOI : 10.1016/j.immuni.2024.03.007.Radio-Activities: Architecture and Broadcasting in Cold War Berlin
Cambridge, MA; London: MIT Press, 2024.No Last One
Revue Matières. 2024. num. 18.All That is Solid
Transcalar Prospects in Climate Crisis; Zurich: Lars Müller, 2024.Characterization of the gut-bone marrow axis through bile acid signaling
Lausanne, EPFL, 2024.Studies of crystal collimation for heavy ion operation at the LHC
Lausanne, EPFL, 2024.Engineering novel protein interactions with therapeutic potential using deep learning-guided surface design
Lausanne, EPFL, 2024.Querying the Digital Archive of Science: Distant Reading, Semantic Modelling and Representation of Knowledge
Lausanne, EPFL, 2024.Hybrid organic/metal-oxide shells on semiconductor nanocrystals via colloidal atomic layer deposition
Lausanne, EPFL, 2024.Electrical and Optical Manifestations of Flat Band Physics in Van der Waals Materials
Lausanne, EPFL, 2024.Plasmonically enhanced molecular junctions for investigation of atomic-scale fluctuations in self-assembled monolayers
Lausanne, EPFL, 2024.Exact Obstacle Avoidance for Robots in Complex and Dynamic Environments Using Local Modulation
Lausanne, EPFL, 2024.S-acylation and lipid exchange at the ER-Golgi membrane contact sites regulate pathogen entry in human cells
Lausanne, EPFL, 2024.Serial Dependence in Human Visual Perception and Decision-Making
Lausanne, EPFL, 2024.Data-Driven Methods for Controller Design in Atomic Force Microscopy
Lausanne, EPFL, 2024.Quantum-mechanical effects in photoluminescence from thin crystalline gold films
Light: Science & Applications. 2024. Vol. 13, num. 91. DOI : 10.1038/s41377-024-01408-2.Quantifying the effects of rainfall temporal variability on landscape evolution processes
EGU 2024, Viena, April 14–19, 2024.Towards a metabolic theory of catchments: scaling of water and carbon fluxes with size
EGU General Assembly 2024, Vienna, Austria, April 14-19, 2024.Biohybrid Superorganisms—On the Design of a Robotic System for Thermal Interactions With Honeybee Colonies
IEEE Access. 2024. Vol. 12, p. 50849-50871. DOI : 10.1109/ACCESS.2024.3385658.Dataset to accompany publication “Quantum-mechanical effects in photoluminescence from thin crystalline gold films”
2024.Impact of CO2-rich seawater injection on the flow properties of basalts
International Journal of Greenhouse Gas Control. 2024-04-19. Vol. 134, p. 104128. DOI : 10.1016/j.ijggc.2024.104128.Architecture of a decentralised decision support system for futuristic beehives
Biosystems Engineering. 2024. Vol. 240, p. 56-61. DOI : 10.1016/j.biosystemseng.2024.02.017.TSLAM: a tag-based object-centered monocular navigation system for augmented manual woodworking.
Construction Robotics. 2024-04-16. Vol. 8, num. 4. DOI : 10.1007/s41693-024-00118-w.Water weakening and the compressive brittle strength of carbonates: Influence of fracture toughness and static friction
International Journal of Rock Mechanics and Mining Sciences. 2024. Vol. 177, p. 105736. DOI : 10.1016/j.ijrmms.2024.105736.Integration of the Pilatus3 detector for soft X-ray diagnostics on TCV
25th Topical Conference on High Temperature Plasma Diagnostics HTPD 2024, Asheville, North Carolina, 21 – 25 April 2024.Siloxide tripodal ligands as a scaffold for stabilizing lanthanides in the +4 oxidation state
Chemical Science. 2024-04-02. DOI : 10.1039/d4sc00051j.High-Permittivity Polysiloxanes for Bright, Stretchable Electroluminescent Devices
Advanced Optical Materials. 2024-04-11. DOI : 10.1002/adom.202400132.An extension of the stochastic sewing lemma and applications to fractional stochastic calculus
Forum Of Mathematics Sigma. 2024-04-11. Vol. 12, p. e52. DOI : 10.1017/fms.2024.32.A bridge between trust and control: computational workflows meet automated battery cycling
Journal Of Materials Chemistry A. 2024-04-03. DOI : 10.1039/d3ta06889g.Capsizing due to friction-induced twist in the failure of stopper knots
Extreme Mechanics Letters. 2024-02-19. Vol. 68, p. 102134. DOI : 10.1016/j.eml.2024.102134.A CTCF-dependent mechanism underlies the Hox timer relation to a segmented body plan
Current Opinion In Genetics & Development. 2024-04-01. Vol. 85, p. 102160. DOI : 10.1016/j.gde.2024.102160.Gradient High-Q Dielectric Metasurfaces for Broadband Sensing and Control of Vibrational Light-Matter Coupling
Advanced Materials. 2024-04-09. DOI : 10.1002/adma.202314279.SOMOphilic alkyne vs radical-polar crossover approaches: The full story of the azido-alkynylation of alkenes
Beilstein Journal Of Organic Chemistry. 2024-04-03. Vol. 20, p. 701-713. DOI : 10.3762/bjoc.20.64.Dielectric elastomer actuator-based valveless pump as Fontan failure assist device: introduction and preliminary study
Interdisciplinary Cardiovascular And Thoracic Surgery. 2024-03-29. Vol. 38, num. 4, p. ivae041. DOI : 10.1093/icvts/ivae041.Tree diversity reduces variability in sapling survival under drought
Journal Of Ecology. 2024-04-08. DOI : 10.1111/1365-2745.14294.Probing structural and dynamic properties of MAPbCl3 hybrid perovskite using Mn2+ EPR
Dalton Transactions. 2024-04-03. DOI : 10.1039/d4dt00116h.Benchmarking machine-readable vectors of chemical reactions on computed activation barriers
Digital Discovery. 2024-03-07. DOI : 10.1039/d3dd00175j.Quantum radio astronomy: Data encodings and quantum image processing
Astronomy And Computing. 2024-02-28. Vol. 47, p. 100796. DOI : 10.1016/j.ascom.2024.100796.Comprehensive Memory Safety Validation: An Alternative Approach to Memory Safety
Ieee Security & Privacy. 2024-04-04. DOI : 10.1109/MSEC.2024.3379947.A Method of Moments Estimator for Interacting Particle Systems and their Mean Field Limit
Siam-Asa Journal On Uncertainty Quantification. 2024-01-01. Vol. 12, num. 2, p. 262-288. DOI : 10.1137/22M153848X.A setup for hard x-ray time-resolved resonant inelastic x-ray scattering at SwissFEL
Structural Dynamics-Us. 2024-03-01. Vol. 11, num. 2, p. 024308. DOI : 10.1063/4.0000236.An aircraft assembly process formalism and verification method based on semantic modeling and MBSE
Advanced Engineering Informatics. 2024-02-20. Vol. 60, p. 102412. DOI : 10.1016/j.aei.2024.102412.Stellar Metallicities and Gradients in the Isolated, Quenched Low-mass Galaxy Tucana
Astrophysical Journal. 2024-04-01. Vol. 965, num. 1, p. 36. DOI : 10.3847/1538-4357/ad25ed.Twisted pair transmission line coil – a flexible, self-decoupled and robust element for 7 T MRI
Magnetic Resonance Imaging. 2024-02-19. Vol. 108, p. 146-160. DOI : 10.1016/j.mri.2024.02.007.3D Printing of Double Network Granular Elastomers with Locally Varying Mechanical Properties
Advanced Materials. 2024-04-04. DOI : 10.1002/adma.202313189.Dopant-additive synergism enhances perovskite solar modules
Nature. 2024-03-04. DOI : 10.1038/s41586-024-07228-z.Proliferation-driven mechanical compression induces signalling centre formation during mammalian organ development
Nature Cell Biology. 2024-04-03. DOI : 10.1038/s41556-024-01380-4.Spin-Reorientation-Driven Linear Magnetoelectric Effect in Topological Antiferromagnet Cu3TeO6
Physical Review Letters. 2024-02-26. Vol. 132, num. 9, p. 096701. DOI : 10.1103/PhysRevLett.132.096701.Is There a Special Role for Ovarian Hormones in the Pathogenesis of Lobular Carcinoma?
Endocrinology. 2024-03-29. Vol. 165, num. 5, p. bqae031. DOI : 10.1210/endocr/bqae031.Stick-slip-to-stick transition of liquid oscillations in a U-shaped tube
Physical Review Fluids. 2024-03-19. Vol. 9, num. 3, p. 034401. DOI : 10.1103/PhysRevFluids.9.034401.Opportunities and challenges in design and optimization of protein function
Nature Reviews Molecular Cell Biology. 2024-04-02. DOI : 10.1038/s41580-024-00718-y.Impact of beam-coupling impedance on the Schottky spectrum of bunched beam
Journal Of Instrumentation. 2024-03-01. Vol. 19, num. 3, p. P03017. DOI : 10.1088/1748-0221/19/03/P03017.Gaussian universality of perceptrons with random labels
Physical Review E. 2024-03-08. Vol. 109, num. 3, p. 034305. DOI : 10.1103/PhysRevE.109.034305.Diffusion of brain metabolites highlights altered brain microstructure in type C hepatic encephalopathy: a 9.4 T preliminary study
Frontiers In Neuroscience. 2024-03-20. Vol. 18, p. 1344076. DOI : 10.3389/fnins.2024.1344076.Teaching about non-deterministic physics: an almost forgotten fundamental contribution of Marie Curie
European Journal Of Physics. 2024-05-01. Vol. 45, num. 3, p. 035803. DOI : 10.1088/1361-6404/ad312e.The angiogenic growth of cities
Journal Of The Royal Society Interface. 2024-04-03. Vol. 21, num. 213, p. 20230657. DOI : 10.1098/rsif.2023.0657.Learning Weakly Convex Regularizers for Convergent Image-Reconstruction Algorithms
Siam Journal On Imaging Sciences. 2024-01-01. Vol. 17, num. 1, p. 91-115. DOI : 10.1137/23M1565243.Euclid: Improving the efficiency of weak lensing shear bias calibration
Astronomy & Astrophysics. 2024-03-28. Vol. 683, p. A240. DOI : 10.1051/0004-6361/202347833.Randomized flexible GMRES with deflated restarting
Numerical Algorithms. 2024-03-28. DOI : 10.1007/s11075-024-01801-3.An interior penalty coupling strategy for isogeometric non-conformal Kirchhoff-Love shell patches
Engineering With Computers. 2024-03-27. DOI : 10.1007/s00366-024-01965-5.Stress tolerance of lightweight glass-free PV modules for vehicle integration
Epj Photovoltaics. 2024-04-01. Vol. 15, p. 10. DOI : 10.1051/epjpv/2024003.On the Arithmetic and Geometric Fusion of Beliefs for Distributed Inference
Ieee Transactions On Automatic Control. 2024-04-01. Vol. 69, num. 4, p. 2265-2280. DOI : 10.1109/TAC.2023.3330405.Alpha1-antitrypsin improves survival in murine abdominal sepsis model by decreasing inflammation and sequestration of free heme
Frontiers In Immunology. 2024-03-18. Vol. 15, p. 1368040. DOI : 10.3389/fimmu.2024.1368040.Quantitative prediction of crystallization in laser powder bed fusion of a Zr-based bulk metallic glass with high oxygen content
Materials & Design. 2024-03-01. Vol. 239, p. 112744. DOI : 10.1016/j.matdes.2024.112744.A cut-cell method for the numerical simulation of 3D multiphase flows with strong interfacial effects
Journal Of Computational Physics. 2024-02-26. Vol. 504, p. 112846. DOI : 10.1016/j.jcp.2024.112846.Speciation of Lanthanide Metal Ion Dopants in Microcrystalline All-Inorganic Halide Perovskite CsPbCl3
Journal Of The American Chemical Society. 2024-03-28. Vol. 146, num. 14, p. 9554-9563. DOI : 10.1021/jacs.3c11427.Can Gas Consumption Data Improve the Performance of Electricity Theft Detection?
Ieee Transactions On Industrial Informatics. 2024-03-18. DOI : 10.1109/TII.2024.3371991.Design and in vitro Characterization of a Wearable Multisensing System for Hydration Monitoring
Ieee Transactions On Instrumentation And Measurement. 2024-01-01. Vol. 73, p. 1-11. DOI : 10.1109/TIM.2024.3369161.Gamma-ray Spectroscopy in Low-Power Nuclear Research Reactors
Journal Of Nuclear Engineering. 2024-03-01. Vol. 5, num. 1, p. 26-43. DOI : 10.3390/jne5010003.Accretion Disk Size and Updated Time-delay Measurements in the Gravitationally Lensed Quasar SDSS J165043.44+425149.3
Astrophysical Journal. 2024-04-01. Vol. 964, num. 2, p. 173. DOI : 10.3847/1538-4357/ad3069.The molecular scale mechanism of deposition ice nucleation on silver iodide
Environmental Science-Atmospheres. 2024-02-15. Vol. 4, num. 2, p. 243-251. DOI : 10.1039/d3ea00140g.Multi-Ported GC-eDRAM Bitcell with Dynamic Port Configuration and Refresh Mechanism
Journal Of Low Power Electronics And Applications. 2024-03-01. Vol. 14, num. 1, p. 2. DOI : 10.3390/jlpea14010002.On the Sums over Inverse Powers of Zeros of the Hurwitz Zeta Function and Some Related Properties of These Zeros
Symmetry-Basel. 2024-03-01. Vol. 16, num. 3, p. 326. DOI : 10.3390/sym16030326.Realization of Organocerium-Based Fullerene Molecular Materials Showing Mott Insulator-Type Behavior
Acs Applied Materials & Interfaces. 2024-03-27. Vol. 16, num. 14, p. 17857-17869. DOI : 10.1021/acsami.3c18766.Mean-field transport equations and energy theorem for plasma edge turbulent transport
Journal Of Plasma Physics. 2024-03-15. Vol. 90, num. 2, p. 905900202. DOI : 10.1017/S0022377824000163.Two- and Three-Dimensional Superconducting Phases in the Weyl Semimetal TaP at Ambient Pressure. (vol 10, 288, 2020)
Crystals. 2024-03-01. Vol. 14, num. 3, p. 264. DOI : 10.3390/cryst14030264.Microbial genome collection of aerobic granular sludge cultivated in sequencing batch reactors using different carbon source mixtures
Microbiology Resource Announcements. 2024-03-27. DOI : 10.1128/mra.00102-24.The Extraordinary March 2022 East Antarctica “Heat” Wave. Part II: Impacts on the Antarctic Ice Sheet
Journal Of Climate. 2024-02-01. Vol. 37, num. 3, p. 779-799. DOI : 10.1175/JCLI-D-23-0176.1.The multimodality cell segmentation challenge: toward universal solutions
Nature Methods. 2024-03-26. DOI : 10.1038/s41592-024-02233-6.Euclid: The search for primordial features
Astronomy & Astrophysics. 2024-03-25. Vol. 683, p. A220. DOI : 10.1051/0004-6361/202348162.Search for Inelastic Dark Matter in Events with Two Displaced Muons and Missing Transverse Momentum in Proton-Proton Collisions at p s=13 TeV
Physical Review Letters. 2024-01-23. Vol. 132, num. 4, p. 041802. DOI : 10.1103/PhysRevLett.132.041802.Tumor-educated Gr1+CD11b+cells drive breast cancer metastasis via OSM/IL-6/JAK-induced cancer cell plasticity
Journal Of Clinical Investigation. 2024-03-15. Vol. 134, num. 6, p. e166847. DOI : 10.1172/JCI166847.Search for Scalar Leptoquarks Produced via τ-Lepton-Quark Scattering in pp Collisions at ffiffi s p=13 TeV
Physical Review Letters. 2024-02-08. Vol. 132, num. 6, p. 061801. DOI : 10.1103/PhysRevLett.132.061801.Measurement of the K+ → π+γγ decay
Physics Letters B. 2024-02-13. Vol. 850, p. 138513. DOI : 10.1016/j.physletb.2024.138513.Dynamics of the charge transfer to solvent process in aqueous iodide
Nature Communications. 2024-03-21. Vol. 15, num. 1, p. 2544. DOI : 10.1038/s41467-024-46772-0.Cortical cell assemblies and their underlying connectivity: An in silico study
Plos Computational Biology. 2024-03-01. Vol. 20, num. 3, p. e1011891. DOI : 10.1371/journal.pcbi.1011891.Disulfide-Cross-Linked Tetra-PEG Gels
Macromolecules. 2024-03-25. Vol. 57, num. 7, p. 3058-3065. DOI : 10.1021/acs.macromol.3c02514.Evaluation of controllers for augmentative hip exoskeletons and their effects on metabolic cost of walking: explicit versus implicit synchronization
Frontiers In Bioengineering And Biotechnology. 2024-03-12. Vol. 12, p. 1324587. DOI : 10.3389/fbioe.2024.1324587.Boosting likelihood learning with event reweighting
Journal Of High Energy Physics. 2024-03-20. num. 3, p. 117. DOI : 10.1007/JHEP03(2024)117.Deconvolution of the X-ray absorption spectrum of trans-1,3-butadiene with resonant Auger spectroscopy
Physical Chemistry Chemical Physics. 2024-03-25. DOI : 10.1039/d4cp00053f.The Extraordinary March 2022 East Antarctica “Heat” Wave. Part I: Observations and Meteorological Drivers
Journal Of Climate. 2024-02-01. Vol. 37, num. 3. DOI : 10.1175/JCLI-D-23-0175.1.Measurement of the τ lepton polarization in Z boson decays in proton-proton collisions at √s=13 TeV
Journal Of High Energy Physics. 2024-01-19. num. 1, p. 101. DOI : 10.1007/JHEP01(2024)101.Light-Controlled Multiconfigurational Conductance Switching in a Single 1D Metal-Organic Wire
Acs Nano. 2024-03-22. DOI : 10.1021/acsnano.3c12909.Redox Properties of Flavin in BLUF and LOV Photoreceptor Proteins from Hybrid QM/MM Molecular Dynamics Simulation
Journal Of Physical Chemistry B. 2024-03-22. Vol. 128, num. 13, p. 3069-3080. DOI : 10.1021/acs.jpcb.3c06245.Field Guide to Northern Tree-related Microhabitats: Descriptions and size limits for their inventory in boreal and hemiboreal forests of Europe and North America
Swiss Federal Institute for Forest, Snow and Landscape Research WSL, Switzerland, 2024.Data Champions Lunch Talks – Green Bytes: Data-Driven Approaches to EPFL Sustainability
Data Champions Lunch Talks – Green Bytes: Data-Driven Approaches to EPFL Sustainability, EPFL, CM 1 221, April 18, 2024.Comparison of Three Viral Nucleic Acid Preamplification Pipelines for Sewage Viral Metagenomics
Food and Environmental Virology. 2024. DOI : 10.1007/s12560-024-09594-3.How to Support Students to Develop Skills that Promote Sustainability
Teaching Transversal Skills for Engineering Studens: A Practical Handbook of Activities with Tangibles; EPFL, 2024.How to Support Students Giving Each Other Constructive Feedback, Especially When It Is Difficult to Hear
Teaching Transversal Skills for Engineering Studens: A Practical Handbook of Activities with Tangibles; EPFL, 2024.How teachers can use the 3T PLAY trident framework to design an activity that develops transversal skills
Teaching Transversal Skills for Engineering Studens: A Practical Handbook of Activities with Tangibles; EPFL, 2024.The conceptual foundations of innate immunity: Taking stock 30 years later
Immunity. 2024-04-09. Vol. 57, num. 4, p. 613-631. DOI : 10.1016/j.immuni.2024.03.007.Radio-Activities: Architecture and Broadcasting in Cold War Berlin
Cambridge, MA; London: MIT Press, 2024.No Last One
Revue Matières. 2024. num. 18.All That is Solid
Transcalar Prospects in Climate Crisis; Zurich: Lars Müller, 2024.Field Guide to Northern Tree-related Microhabitats: Descriptions and size limits for their inventory in boreal and hemiboreal forests of Europe and North America
Swiss Federal Institute for Forest, Snow and Landscape Research WSL, Switzerland, 2024.Data Champions Lunch Talks – Green Bytes: Data-Driven Approaches to EPFL Sustainability
Data Champions Lunch Talks – Green Bytes: Data-Driven Approaches to EPFL Sustainability, EPFL, CM 1 221, April 18, 2024.Comparison of Three Viral Nucleic Acid Preamplification Pipelines for Sewage Viral Metagenomics
Food and Environmental Virology. 2024. DOI : 10.1007/s12560-024-09594-3.How to Support Students to Develop Skills that Promote Sustainability
Teaching Transversal Skills for Engineering Studens: A Practical Handbook of Activities with Tangibles; EPFL, 2024.How to Support Students Giving Each Other Constructive Feedback, Especially When It Is Difficult to Hear
Teaching Transversal Skills for Engineering Studens: A Practical Handbook of Activities with Tangibles; EPFL, 2024.How teachers can use the 3T PLAY trident framework to design an activity that develops transversal skills
Teaching Transversal Skills for Engineering Studens: A Practical Handbook of Activities with Tangibles; EPFL, 2024.The conceptual foundations of innate immunity: Taking stock 30 years later
Immunity. 2024-04-09. Vol. 57, num. 4, p. 613-631. DOI : 10.1016/j.immuni.2024.03.007.Radio-Activities: Architecture and Broadcasting in Cold War Berlin
Cambridge, MA; London: MIT Press, 2024.No Last One
Revue Matières. 2024. num. 18.All That is Solid
Transcalar Prospects in Climate Crisis; Zurich: Lars Müller, 2024.
Storage
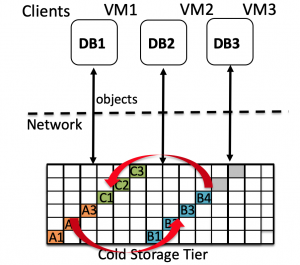
Enterprise databases use storage tiering to lower capital and operational expenses. In such a setting, data waterfalls from an SSD-based high-performance tier when it is “hot” (frequently accessed) to a disk-based capacity tier and finally to a tape-based archival tier when “cold” (rarely accessed). To address the unprecedented growth in the amount of cold data, hardware vendors introduced new devices named Cold Storage Devices (CSD) explicitly targeted at cold data workloads. With access latencies in tens of seconds and cost/GB as low as $0.01/GB/month, CSD provide a middle ground between the low-latency (ms), high-cost, HDD-based capacity tier, and high-latency (min to h), low-cost, tape-based, archival tier.
In this research, we examine the use of CSD as a replacement for both capacity and archival tiers of enterprise databases. While CSD offer major cost savings, current database systems can suffer from severe performance drop when CSD are used as a replacement for HDD due to the mismatch between design assumptions made by the query execution engine and actual storage characteristics of the CSD. We build a CSD-driven query execution framework, called Skipper, that modifies both the database execution engine and CSD scheduling to be able to benefit both from the low cost of CSD without sacrificing its high latency cost. Results show that our implementation of the architecture based on PostgreSQL and OpenStack Swift, is capable of completely masking the high latency overhead of CSD, thereby opening up CSD for wider adoption as a storage tier for cheap data analytics over cold data.